변경 영향 시뮬레이션으로 배포 전 규칙 변경 테스트하기
규칙 변경이 운영에 닿기 전에 실제 과거 주문으로 전체 영향을 측정하고, 그 근거로 배포 여부를 판단하는 방법.
문제
규칙 변경은 화면에서는 한 글자, 장부에서는 수만 달러일 수 있습니다.
마케팅이 신규 고객 웰컴 할인을 10%에서 15%로 올려 달라고 요청합니다. 코드베이스에서 이건 상수 하나입니다. 0.10이 0.15가 됩니다. 컴파일되고, 단위 테스트는 초록색을 유지하고, 변경은 화요일 오후에 배포됩니다.
3주 뒤 재무가 월 정산을 하다가 수익 구멍을 발견합니다. 웰컴 할인이 책정해 둔 예산보다 더 나갔습니다. 한 글자짜리 변경에는 아무도 재지 않은 파급 범위가 있었습니다. 3주 동안 모든 신규 고객 주문에 적용됐고, 늘어난 5%포인트는 변경 전에 아무도 들여다보지 않은 물량 위에서 쌓였습니다.
코드에는 잘못이 없었습니다. 상수는 정확했습니다. 빠져 있던 것은 코드 혼자서는 답할 수 없는 질문의 답입니다. 지난달 주문 전체에 적용했다면 이 변경은 얼마가 들었을까? 이 질문은 실제 데이터 위의 집계 거동에 대한 것이고, 서비스 안의 상수에는 그 답을 배포 전에 보여줄 방법이 없습니다.
이 패턴이 답하는 질문은 이것입니다. 규칙 변경이 운영에 닿기 전에 실제 과거 주문으로 전체 영향을 어떻게 측정하고, 그 근거로 배포 여부를 어떻게 결정하는가.
단순한 접근
첫 버전은 할인을 상수로 두고 그 자리에서 바꿉니다.
public BigDecimal applyWelcomeDiscount(Order order, Customer customer) {
BigDecimal subtotal = order.getSubtotal();
// 신규 고객 웰컴 할인.
// 마케팅이 0.10에서 0.15로 올려 달라고 요청.
if (customer.getSegment() == Segment.NEW) {
BigDecimal rate = new BigDecimal("0.15"); // 직전 0.10
return subtotal.subtract(subtotal.multiply(rate));
}
return subtotal;
}
diff는 한 줄이고, 절차를 붙이기엔 너무 작아 보이는 종류의 변경입니다. 그 느낌이 함정입니다. 문제는 정확성이 아닙니다. 새 요율은 매칭되는 모든 주문에 정확히 적용됩니다. 문제는 아무도 크기를 재지 않은 채 변경이 나간다는 것이고, 그것이 세 군데에서 드러납니다.
- 단위 테스트는 엉뚱한 것을 증명합니다. $100짜리 신규 고객 주문이 $85를 반환한다고 단언하는 테스트가 있습니다. 통과하지만 이 결정에는 쓸모가 없습니다. 케이스 하나를 확인할 뿐 집계를 확인하지 않기 때문입니다. 어떤 단위 테스트도 "0.15가 지난달 4만 건의 주문에 무슨 일을 하는가"에는 답하지 못합니다. 가장 중요한 것을 테스트가 보지 못합니다.
- 파급 범위는 운영이 시험대가 되기 전까지 보이지 않습니다. 이 변경의 첫 실측은 몇 주 뒤의 재무 정산입니다. 결과를 알게 되는 장소가 운영 환경이 됐고, 피드백 루프는 한 달짜리입니다.
- 결정의 기록이 없습니다. 재무가 웰컴 할인이 왜 초과됐는지 물으면, 답은 상수에 대한
git blame과 Slack 스레드의 기억뿐입니다. 특정 날짜에 적용 중이던 요율과 그 영향은 조회할 수 있는 어디에도 적힌 적이 없습니다.
패턴 정의
해법은 변경을 배포 전에 측정할 수 있는 대상으로 만드는 것입니다. 할인을 규칙으로 모델링하고, 제안된 변경을 별도 버전으로 다루고, 현재 버전과 제안 버전을 나란히 둡니다.
LexQ 관점에서 이 시나리오는 세 개념에 대응됩니다.
- 팩트: 엔진이 읽는 입력.
customer_segment,purchase_subtotal_usd. - 규칙: 웰컴 할인 규칙 하나. 조건과,
purchase_subtotal_usd에서 일정 비율을 차감하는MUTATE_FACT(값 변경) 액션을 가집니다. - 버전: 전체 규칙의 불변 스냅샷. 비교 기준 버전은 운영 중인 10% 규칙을, 대상 버전은 제안된 15% 규칙을 담습니다. 대상 버전의 어떤 것도 배포 전까지 운영에 닿지 않습니다.
규칙 자체는 평범합니다. 여기에는 상호 배타 그룹(Mutex Group)도 없습니다. 경쟁할 것이 없기 때문입니다. 할인 하나는 주문에 적용되거나 적용되지 않거나 둘 중 하나입니다.
{
"name": "Welcome discount: new customers 15%",
"condition": {
"type": "GROUP",
"operator": "AND",
"children": [
{
"type": "SINGLE",
"field": "customer_segment",
"operator": "EQUALS",
"value": "NEW",
"valueType": "STRING"
}
]
},
"actions": [
{
"type": "MUTATE_FACT",
"parameters": {
"rate": 15,
"method": "PERCENTAGE",
"refVar": "purchase_subtotal_usd",
"operator": "SUB",
"rounding": { "mode": "HALF_UP", "scale": 2 }
}
}
],
"isEnabled": true
}
비교 기준 버전은 rate가 10인 것 말고는 동일합니다. 운영 중인 버전을 복제하고 그 규칙 하나를 고치면 대상 버전이 됩니다. 복제된 버전은 자체 ID를 가진 실제 버전이라 무엇이든 실행해 볼 수 있지만, 배포 전까지는 트래픽을 받지 않습니다.
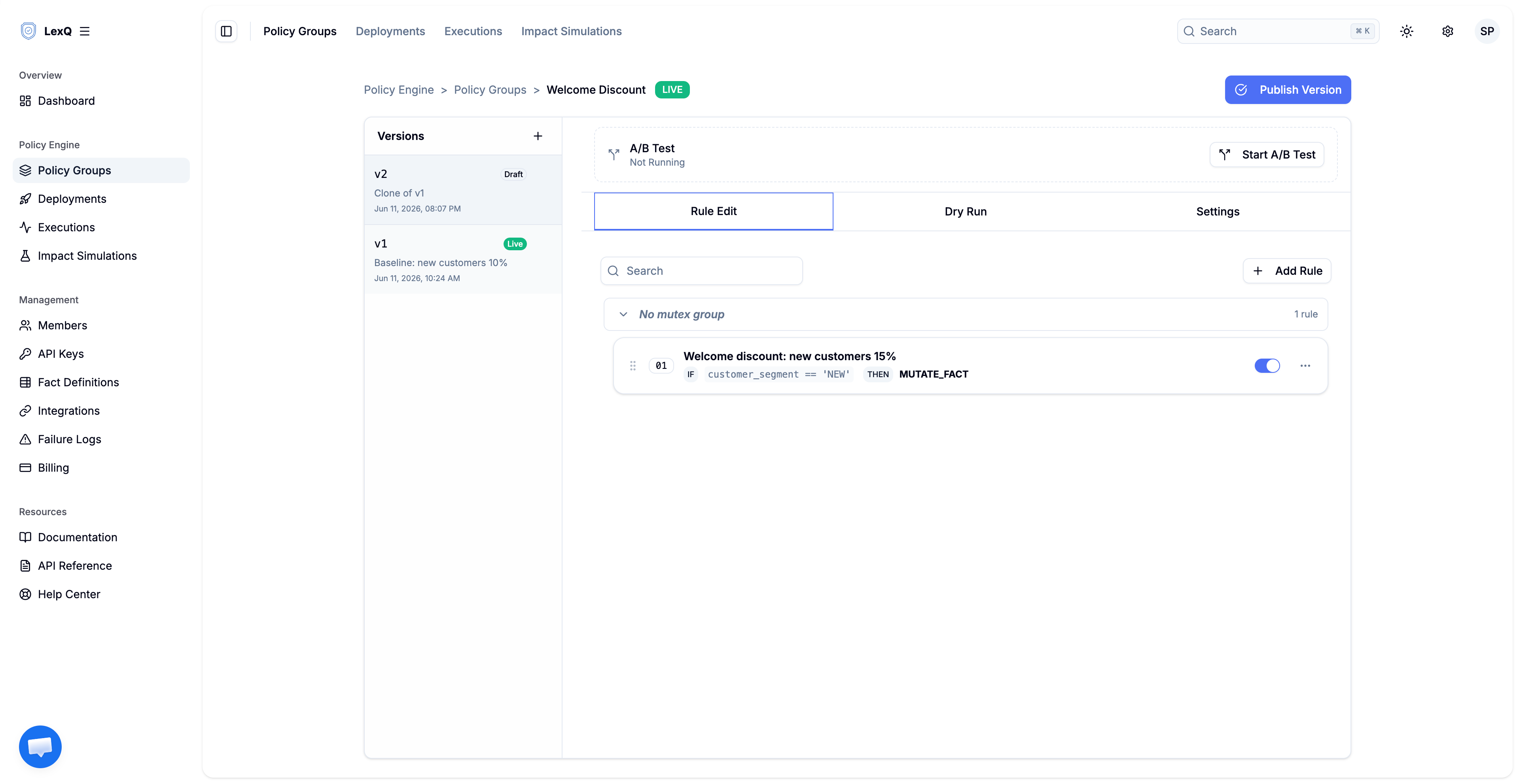
이것이 변경 영향 시뮬레이션이 요구하는 설정의 전부입니다. 평가하려는 변경만큼만 차이 나는 두 버전.
변경 영향 시뮬레이션 전략
변경 영향 시뮬레이션은 단위 테스트가 답하지 못한 질문에 답합니다. 실제 주문 위에서 대상 버전은 비교 기준 버전과 무엇이 달라지는가. 과거 실행 데이터의 한 구간을 지정하고, 비교 기준 버전을 옆에 둔 채 대상 버전을 그 위에 실행합니다.
데이터셋은 이력 데이터(실행 로그)입니다. 엔진이 과거에 실제로 처리한 주문이며, 대표성을 가질 만큼 충분히 긴 기간을 포함해야 합니다. 직전 한 달 전체가 무난한 기본값입니다. 각 레코드에는 실제 주문이 보냈던 팩트(customer_segment, purchase_subtotal_usd)가 담겨 있어, 그 트래픽에 대상 버전을 적용했다면 어떤 결과가 나왔을지를 그대로 재현합니다.
lexq analytics simulation start --json '{
"policyVersionId": "<candidate-version-id>",
"dataset": {
"type": "HISTORICAL",
"source": "EXECUTION_LOGS",
"from": "2026-05-01",
"to": "2026-05-31"
},
"options": {
"baselinePolicyVersionId": "<baseline-version-id>",
"includeRuleStats": true,
"maxRecords": 40000,
"metricConfig": {
"targetVariable": "purchase_subtotal_usd__delta",
"aggregationType": "SUM"
}
}
}'
실행은 모든 레코드를 두 버전 모두에 재생하고, 이 결정에 중요한 세 가지를 보고합니다.
- 집계 지표.
metricConfig는 데이터셋 전체에 걸쳐 버전별로purchase_subtotal_usd__delta를 합산합니다. 주문 하나의__delta는 그 주문이 받은 할인(음수)이고, 합계는 지급된 총 할인입니다. 대상 버전의 합계에서 비교 기준 버전의 합계를 뺀 값이, 이 요율 변경이 지난달에 추가로 쓰게 했을 할인입니다. 배포 전에 달러로 확인하는 파급 범위입니다. - 매칭률. 규칙별 통계 포함(
includeRuleStats)을 켜면 웰컴 규칙이 얼마나 자주 발동했는지가 함께 보고됩니다. 이 비율은 곧 신규 고객 주문의 비중입니다. 비즈니스가 아는 비중보다 눈에 띄게 높다면 애플리케이션이 보내는customer_segment팩트부터 의심해야 하고, 그건 배포 뒤가 아니라 배포 전에 알아야 할 일입니다. - 대상 버전과 비교 기준 버전, 나란히. 콘솔이 두 버전의 수치를 한 화면에 보여주므로, 차이를 손으로 계산할 필요 없이 그대로 읽습니다.
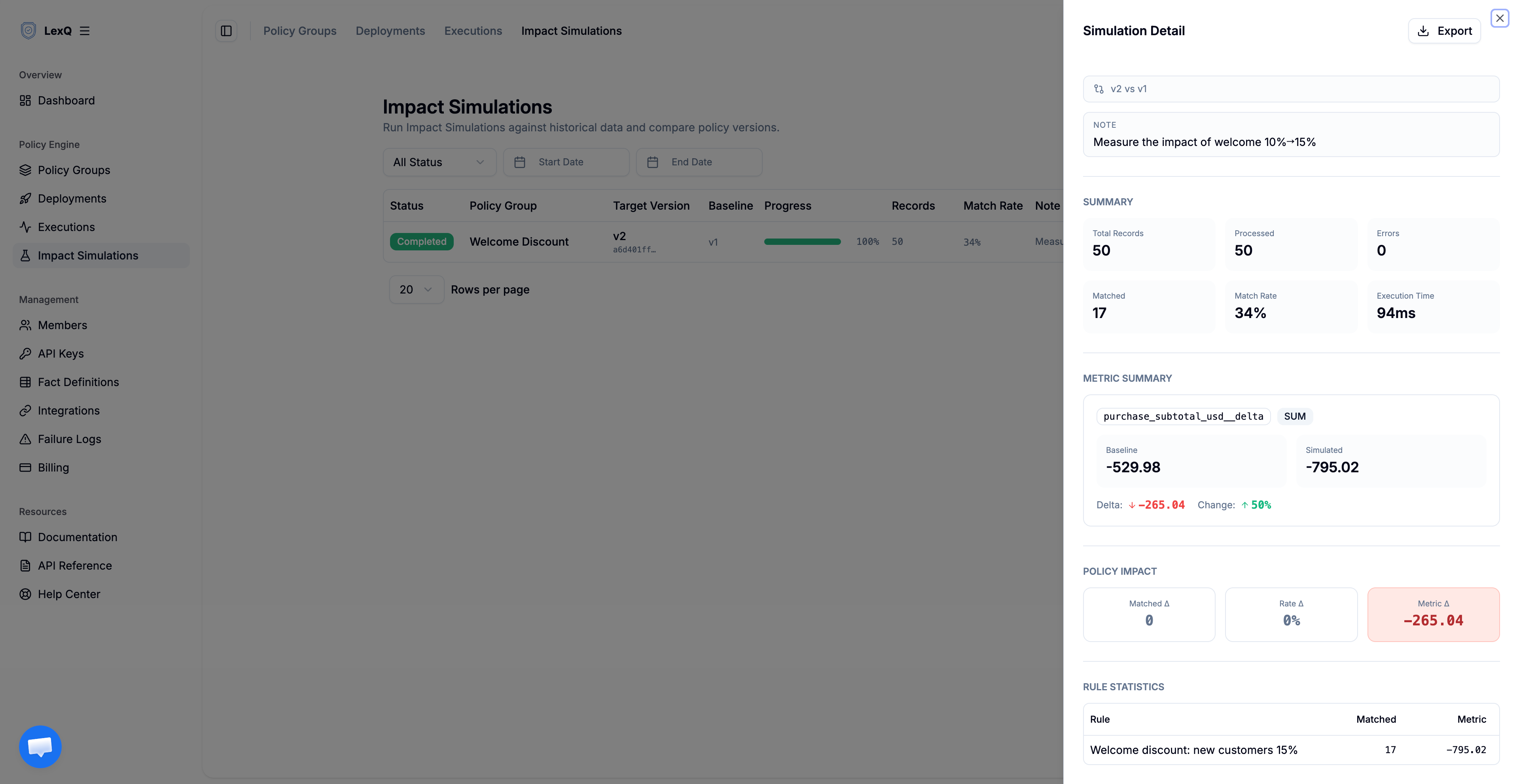
배포 여부는 두 조건이 결정합니다. 첫째, 추가 집계 할인(대상 버전의 합산 __delta에서 비교 기준 버전의 값을 뺀 차이)이 팀이 신규 고객 할인에 쓰기로 한 예산 한도 안에 들어와야 합니다. 시뮬레이션이 그 한도를 넘는다고 말하면, 운영 주문이 단 한 건도 영향받기 전에 결정이 끝납니다. 둘째, 매칭률이 예상하는 신규 고객 주문 비중과 비슷해야 합니다. 차이가 크다면 운영에서 들어오는 팩트가 가정과 다르게 생겼다는 뜻입니다. 시뮬레이션 중에 외부 호출은 모킹 처리되어 연동이 실제로 호출되지 않습니다. 실행은 과거 데이터를 읽기만 하고 아무것도 쓰지 않습니다. 부작용이 없습니다.
아직 운영 트래픽이 없다면 파일 업로드로 대표 데이터셋을 올려 같은 비교를 돌립니다. 예상하는 소계 범위에 걸쳐 신규·기존 고객군을 고르게 담으면 됩니다.
의사결정 트레이스 출력
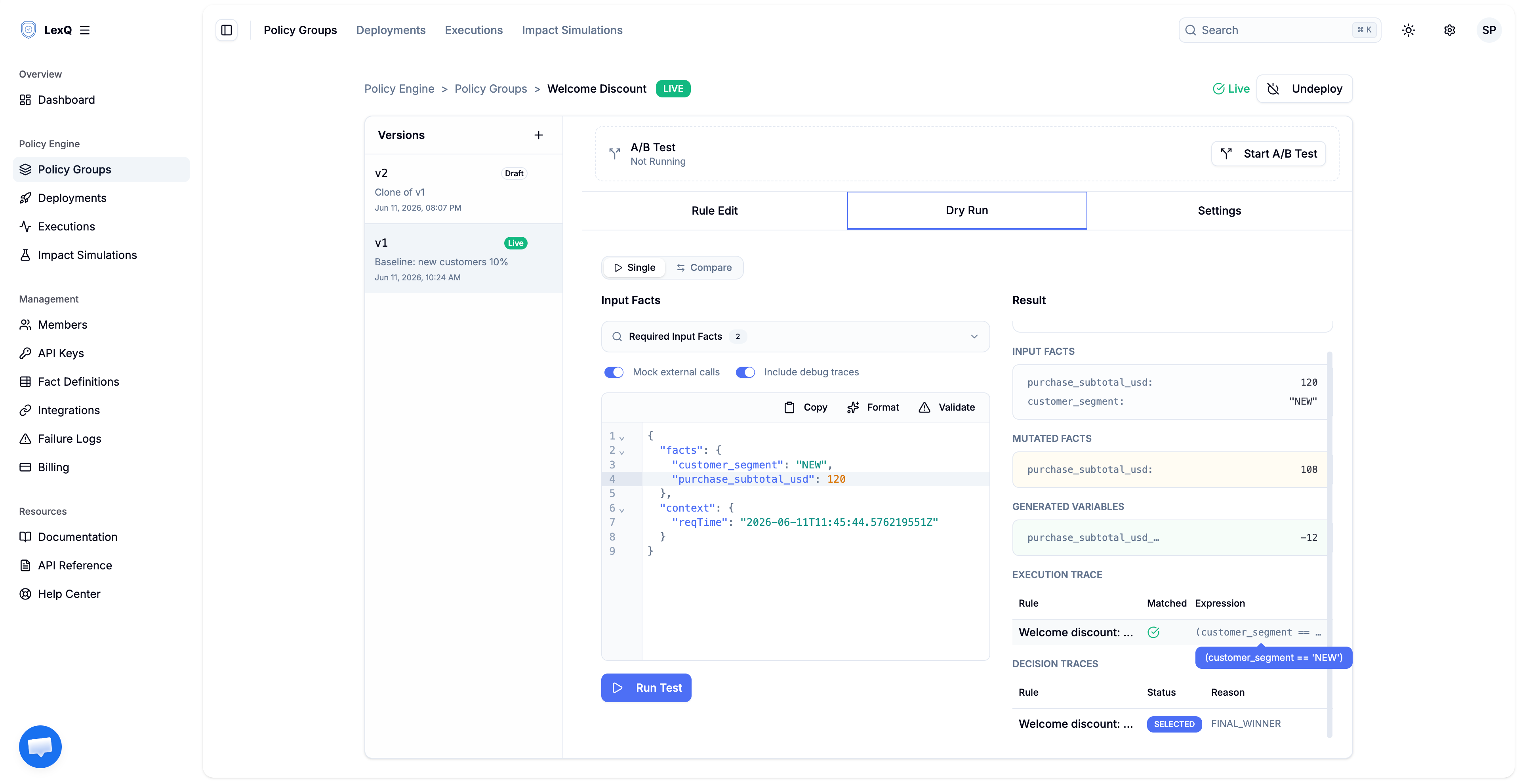
집계 숫자는 개별 결정들의 합이고, 그 하나하나를 들여다볼 수 있습니다. $120 장바구니를 든 신규 고객 주문 하나를 대상 버전에 드라이런으로 실행합니다.
{
"result": "SUCCESS",
"data": {
"traceId": "9f2c41a8-...",
"inputFacts": {
"customer_segment": "NEW",
"purchase_subtotal_usd": 120.00
},
"mutatedFacts": {
"purchase_subtotal_usd": 102.00
},
"generatedVariables": {
"purchase_subtotal_usd__delta": -18.00
},
"executionTraces": [ ... ],
"decisionTraces": [
{
"ruleName": "Welcome discount: new customers 15%",
"status": "SELECTED",
"reasonCode": "FINAL_WINNER",
"reasonDetail": null
}
]
}
}

mutatedFacts에는 할인 적용 후의 구매 소계(purchase_subtotal_usd) 102.00이 담깁니다. generatedVariables의 purchase_subtotal_usd__delta는 -18.00, 정확히 120의 15%이며, 이 주문 하나가 시뮬레이션 집계에 보태는 바로 그 금액입니다. 관계는 직접적입니다. 시뮬레이션의 달러 수치는 이런 주문별 변화량의 합입니다. 의사결정 트레이스에서 웰컴 규칙은 선택됨(SELECTED)이고 사유는 최종 승자(FINAL_WINNER)입니다. 이 규칙이 어떤 조건식으로 평가됐는지는 위 드라이런 화면의 실행 트레이스 표에 함께 보입니다. 이것이 감사 대응의 답입니다. 6개월 뒤에도 트레이스가 디버거 없이 $18을 설명합니다.
같은 주문을 비교 기준 버전(10%)에 실행하면 변화량은 -12.00, 소계는 108.00입니다. 이 한 주문의 $6 차이에 그달의 매칭된 주문 수를 곱한 것이, 시뮬레이션이 집계로 보고한 추가 비용입니다. 기존 고객의 주문은 어느 규칙에도 매칭되지 않아 미매칭(NO_MATCH) · 조건 미충족(CONDITION_MISMATCH)으로 기록되고, 두 버전 어디서도 할인을 받지 않습니다. 그래서 요율 값만이 아니라 매칭률이 집계를 움직입니다.
엣지 케이스
이 패턴의 본체는 할인이 아니라 시뮬레이션 워크플로우입니다. 인접한 몇 가지 경우는 의도적인 선택을 요구합니다.
- 지표를 고르는 일.
purchase_subtotal_usd__delta의 SUM은 "지급된 총 할인"에 답합니다. 질문이 다르면 설정도 다릅니다. "주문당 평균 할인"이면 AVG, "영향받은 주문 수"면 규칙별 통계의 매칭 횟수를 봅니다. 실제로 던지는 질문에 맞는 집계를 고르고 부호를 확인합니다. 할인의 변화량은 음수이므로, 할인이 커질수록 합계는 더 작은(더 음수인) 값이 됩니다. - 비결정적 규칙. 결과가 현재 시각이나 난수에 의존하는 규칙은 동일하게 재현되지 않습니다. 과거 기록에는 그 입력의 한 번의 결과만 남아 있기 때문입니다. 규칙이 읽는 팩트는 명시적이고 결정적으로 유지합니다. 시간 의존이 불가피하다면, 그 의존성이 안정적인 기간 안에서만 시뮬레이션합니다.
- 깨끗한 데이터셋이 아니라 대표 데이터셋. 운영 로그 대신 파일을 업로드할 때는 깨끗한 케이스만 담고 싶은 유혹이 생깁니다. 집계를 움직이는 건 가장자리 케이스입니다. 가장 큰 장바구니, 고객군 경계. 그것들이 빠진 데이터셋은 안전해 보이는, 그러나 틀린 숫자를 만듭니다.
- 표본 크기. 최대 레코드 수(
maxRecords)가 실행 범위를 자릅니다. 드물지만 금액이 큰 고객군을 놓칠 만큼 작은 한도는, 엉뚱한 모집단에 대한 자신 있는 답을 만듭니다. 변경이 실제로 닿을 물량을 덮도록 기간과 한도를 잡습니다. - 시뮬레이션은 읽기 전용입니다. 실행 중 외부 호출은 모킹 처리됩니다. 웹훅을 호출하거나 알림을 발송하는 규칙이 있어도 시뮬레이션에서는 실제로 나가지 않습니다. 집계는 외부 효과 없이 계산되고, 그래서 한 달치 데이터를 반복해서 돌려도 안전합니다.
운영 배포
두 조건을 통과한 대상 버전은 운영에 배포합니다. 배포 시점의 규칙 스냅샷은 해시로 봉인되어 무결성이 검증되고, 누가 언제 어떤 버전을 올렸는지가 기록에 남습니다. 전체 트래픽을 한 번에 바꾸는 대신 점진적으로 노출하려면, 현재 운영 중인 버전과 대상 버전 사이에 A/B 테스트를 켜고 대상 버전의 트래픽 비율을 5% → 25% → 50%로 단계적으로 올립니다. 각 단계에서 운영 의사결정 트레이스와 누적 집계를 확인하고, 운영 수치가 시뮬레이션을 따라갈 때만 다음 비율로 넘어갑니다. 수치가 유지되면 대상 버전을 배포해 나머지 트래픽 전부를 전환합니다.
다음 두 신호 중 하나라도 보이면 즉시 롤백합니다:
- 트래픽이 늘어나는 동안 운영 집계 할인이 시뮬레이션 예측에서 벗어날 때. 운영 모집단이 시뮬레이션에 쓴 과거 기간과 다르다는 뜻이고, 승인했던 파급 범위는 더 이상 유효하지 않습니다.
- 웰컴 규칙의 발동 비율이 시뮬레이션 매칭률과 크게 다를 때. 운영에서 애플리케이션이 보내는
customer_segment팩트가 데이터셋에 담겼던 것과 다르게 생겼다는 뜻입니다.
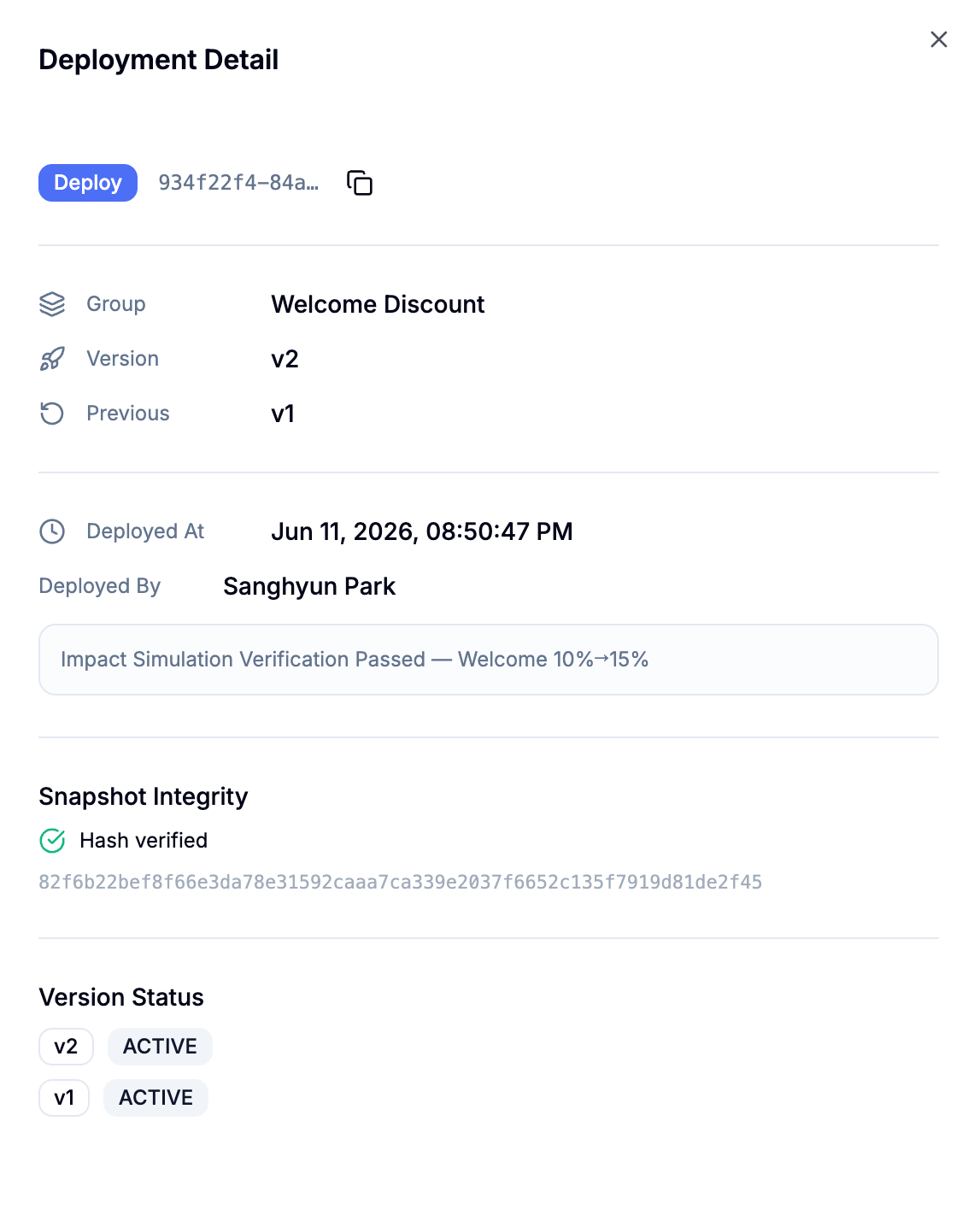
롤백하면 정책 그룹이 이전 버전으로 되돌아가고, 롤백한 사실 자체도 배포 이력에 남습니다. 되돌린 것까지 감사 기록에 남는 셈입니다. 대상 버전이 전체 트래픽을 받으며 안정되면, 규칙별 통계가 웰컴 규칙의 운영 매칭률과 실현된 집계를 보여줍니다. 시뮬레이션이 예측했던 바로 그 두 숫자가 이제 실측값입니다. 예측과 실측의 차이가 다음 변경에 가져갈 보정값입니다.
LexQ가 어떻게 동작하는지 playground에서 직접 확인해보세요.