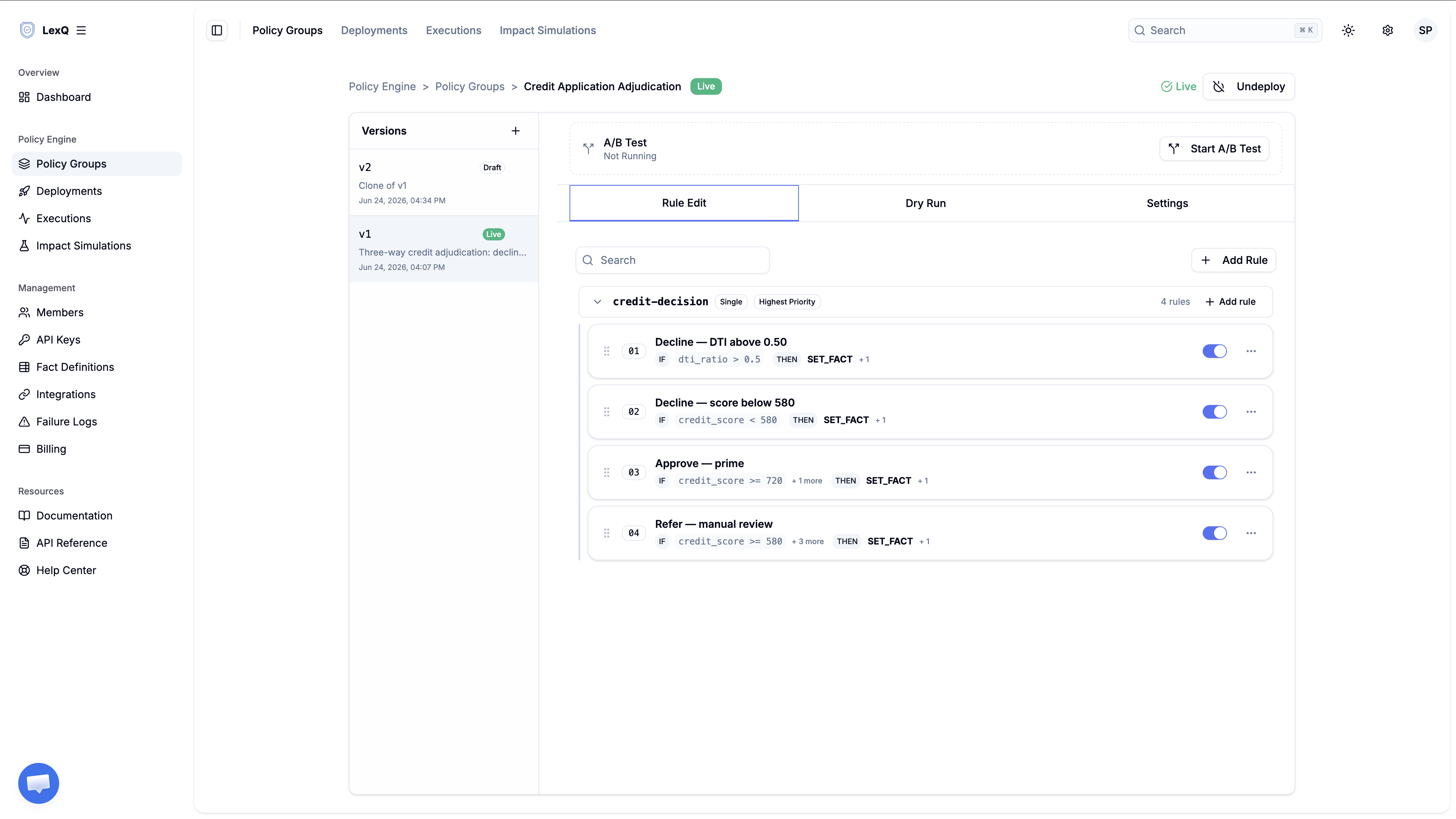
우선순위 상호 배타 그룹으로 신용 신청 판정하기
신용 신청 하나를 승인·거부·조건부 중 하나로 가르고, 어느 규칙이 그 결정을 내렸는지까지 남기는 패턴.
문제
대출 기관은 신청 한 건마다 승인할지, 거부할지, 아니면 사람이 한 번 더 들여다볼지를 정합니다. 신용점수, 연 소득, DTI(부채 대비 소득 비율) 같은 신호 몇 개를 보고 정하는데, 이 신호를 어떤 결과로 연결할지 가르는 기준값이 곧 정책입니다. 기준값은 엔지니어링이 정하는 게 아닙니다. 리스크 부서가 정하고, 주기적으로 들여다보고, 자기 일정에 맞춰 바꿉니다.
이 판단은 차단 다음 단계입니다. KYC 등급별 이체 한도 집행은 "이 이체를 진행해도 되는가"만 가리면 됐습니다. 승인 심사는 다릅니다. 결과가 여러 개라, 그중 어디로 보낼지와 그렇게 정한 근거를 함께 답해야 합니다.
코드로 옮기면 기준값은 상수가 되고, 결과는 if 분기로 갈립니다. 문제는 신호끼리 겹친다는 점입니다. 점수는 높은데 부채 비율도 높은 신청자는 얼마든지 있고, 이 둘은 서로 반대쪽 결과를 가리킵니다. if-else에서는 맨 먼저 조건이 맞는 분기에서 결과가 정해지고 끝납니다. 그러니 어떤 검사를 위에 뒀느냐가 곧 판정을 가릅니다. 승인 검사를 부채 비율 검사보다 위에 두면, 점수 760에 부채 비율 55%인 신청자는 부채 비율 상한이 실행되기도 전에 승인되어 버립니다. 원래대로라면 이 상한에 걸러졌어야 할 신청인데도요. 누가 그렇게 정한 게 아닙니다. 검사 순서가 어느새 정책 노릇을 하고 있을 뿐, 아무도 그렇게 적어 둔 적은 없습니다.
대가는 하나 더 있는데, 이쪽은 한참 뒤에야 드러납니다. 신청이 거부되면 신청자는 그 사유를 들을 권리가 있고, 대출 기관은 몇 달이 지난 뒤에도 어느 규칙이 그 신청을 그렇게 판정했는지, 다른 규칙은 왜 밀렸는지 내놓을 수 있어야 합니다. 로그 한 줄을 뒤져 손으로 짜 맞춘 거부 사유로는, 기관이 그 결정을 책임지기 어렵습니다.
이 패턴이 풀려는 문제가 바로 이것입니다. 신청 하나하나를 승인·거부·조건부 중 정확히 한 곳으로 보내고, 몇 달이 지난 뒤에도 그 신청을 어떤 규칙이 어떤 이유로 그렇게 판정했고 다른 규칙은 왜 밀렸는지까지 답할 수 있게 만드는 것.
단순한 접근
처음에는 기준값을 검사 코드 바로 옆, 결정 서비스의 상수로 둡니다.
public class CreditDecisionService {
// 기준값. 리스크 부서가 관리합니다.
private static final int SCORE_FLOOR = 580;
private static final int SCORE_PRIME = 720;
private static final BigDecimal DTI_CEILING = new BigDecimal("0.50");
private static final BigDecimal MIN_INCOME = new BigDecimal("40000");
public Decision adjudicate(Application app) {
int score = app.getCreditScore();
BigDecimal dti = app.getDtiRatio();
BigDecimal income = app.getAnnualIncomeUsd();
// 이 검사들의 순서가 곧 정책입니다.
// 하지만 그 순서를 정한 사람은 없습니다. 메서드가 그렇게 작성됐을 뿐입니다.
if (score >= SCORE_PRIME && income.compareTo(MIN_INCOME) >= 0) {
return Decision.APPROVE;
}
if (dti.compareTo(DTI_CEILING) > 0) {
return Decision.DECLINE;
}
if (score < SCORE_FLOOR) {
return Decision.DECLINE;
}
return Decision.REFER;
}
}
개발자가 머릿속에 그린 신청에는 이대로도 잘 돌아갑니다. 문제는 구조에 있고, 세 군데에서 드러납니다.
- 검사 순서가 곧 정책인데, 그 정책이 눈에 보이지 않습니다. 승인 분기가 맨 위에 있으면 점수 760에 부채 비율 55%인 신청자는
APPROVE로 반환되고, 부채 비율 상한은 거치지도 않습니다. 부채 비율 검사를 위로 올리면 같은 신청자가 거부됩니다. 결과가 뒤집혔는데 빨갛게 변하는 테스트는 하나도 없습니다. 그 결과를 뒤집은 건, 아무도 "결정"이라고 부르지 않은 순서 바꾸기 한 번이었습니다. - 기준값을 바꾸려면 배포를 해야 합니다. 리스크는 적용 시점을 정하지만, 상수는 배포 일정에 실려 나갑니다. 고객이 실제로 적용받는 기준값은 어느 배포가 먼저 나갔는지에 따라 갈리고, 기준값이 어떻게 바뀌어 왔는지는 서비스의 git 로그에 남습니다.
- 거부가 나중에 찾아볼 기록을 남기지 않습니다. "이 신청은 왜 거부됐는가"는 기록이 됐다 해도 로그 한 줄입니다. "5월에 부채 비율 상한에 막힌 신청을 전부"는 로그를 파헤치는 작업이 되고, 손으로 짜 맞춰야 하는 거부 사유는 대출 기관이 믿고 쓸 수 없는 사유입니다.
패턴 정의
해결의 핵심은 구조에 있습니다. 결과마다 규칙 하나로 만들고, 결정을 내리는 규칙을 모두 하나의 EXCLUSIVE 상호 배타 그룹에 넣은 뒤, 둘 이상이 걸리면 규칙 우선순위가 그중 하나만 선택하게 합니다.
LexQ에서는 이 구조가 세 가지 개념으로 나뉩니다.
- 팩트: 엔진이 읽는 입력값입니다.
credit_score,annual_income_usd,dti_ratio. - 규칙: 결과마다 규칙 하나입니다. 조건과, 결정을 기록하는
SET_FACT액션으로 이루어집니다. 결정은 계산 결과가 아니라 범주라서, 액션은 숫자를 바꾸는 대신 문자열을 적습니다. - 상호 배타 그룹(Mutex Group): 여러 결과 가운데 정확히 하나만 선택되도록 경쟁시키는 필드입니다.
KYC 차단과 갈리는 지점이 여기입니다. KYC에서는 계정의 인증 등급이 하나뿐이라 조건들이 입력을 알아서 갈라놓고, 한 이체에 걸리는 규칙은 많아야 하나입니다. 상호 배타 그룹이 필요 없습니다. 여기서는 신호가 겹칩니다. 부채 비율로 거절하는 규칙과 점수로 승인하는 규칙이 같은 신청자에게 동시에 걸릴 수 있습니다. 두 규칙이 함께 걸려 정반대 결정을 내리니, 무언가가 하나를 고르고 나머지에 무슨 일이 있었는지 남겨야 합니다. 그 무언가가 상호 배타 그룹입니다. 상호 배타 그룹 자체가 어떻게 동작하는지는 VIP 등급 할인 중첩 해소에서 다루고, 이 패턴은 그것을 세 갈래 결정에 가져다 씁니다.
결정 규칙은 모두 같은 mutexGroup 키 credit-decision을 답니다. mutexMode가 EXCLUSIVE라, 선택된 규칙의 액션만 실행됩니다. mutexStrategy는 HIGHEST_PRIORITY라서, 걸린 규칙 중 priority 숫자가 가장 작은 규칙이 선택됩니다.
priority는 규칙을 만들 때 정하는 값이 아닙니다. 버전 안에서 1..N으로 자동으로 매겨지는 순서이고, 순서 바꾸기(콘솔에서 드래그)로만 바뀝니다. 그룹 안에서 매기는 순위가 아니라, 버전 전체에 걸친 하나의 순번입니다. 거절 규칙을 먼저 만들어 위에 올려 두면 가장 작은 priority를 받습니다. 거절과 승인이 함께 걸리면 거절이 선택되는데, 여신 심사에서는 이게 맞는 판단입니다. 상한을 넘는 부채 비율은 점수가 아무리 높아도 결격이니까요.
우선순위가 가장 높은 규칙은 부채 비율 거절입니다.
{
"name": "Decline — DTI above 0.50",
"condition": {
"type": "GROUP",
"operator": "AND",
"children": [
{
"type": "SINGLE",
"field": "dti_ratio",
"operator": "GREATER_THAN",
"value": 0.50,
"valueType": "NUMBER"
}
]
},
"actions": [
{
"type": "SET_FACT",
"parameters": { "key": "credit_decision", "value": "DECLINED" }
},
{
"type": "SET_FACT",
"parameters": { "key": "decision_reason", "value": "Debt-to-income ratio above 0.50" }
}
],
"mutexGroup": "credit-decision",
"mutexMode": "EXCLUSIVE",
"mutexStrategy": "HIGHEST_PRIORITY",
"mutexLimit": 1,
"isEnabled": true
}
점수 하한 거절도 모양은 같습니다. credit_score가 580 미만이라는 조건 하나로, DECLINED와 사유 Score below 580을 적습니다. 두 번째에 둡니다.
승인 규칙은 신호 두 개를 함께 읽습니다.
{
"name": "Approve — prime",
"condition": {
"type": "GROUP",
"operator": "AND",
"children": [
{
"type": "SINGLE",
"field": "credit_score",
"operator": "GREATER_THAN_OR_EQUAL",
"value": 720,
"valueType": "NUMBER"
},
{
"type": "SINGLE",
"field": "annual_income_usd",
"operator": "GREATER_THAN_OR_EQUAL",
"value": 40000,
"valueType": "NUMBER"
}
]
},
"actions": [
{
"type": "SET_FACT",
"parameters": { "key": "credit_decision", "value": "APPROVED" }
},
{
"type": "SET_FACT",
"parameters": { "key": "decision_reason", "value": "Score 720+ with income 40000+" }
}
],
"mutexGroup": "credit-decision",
"mutexMode": "EXCLUSIVE",
"mutexStrategy": "HIGHEST_PRIORITY",
"mutexLimit": 1,
"isEnabled": true
}
조건부 규칙은 맨 뒤에 오고, 점수 구간을 빈틈없이 메웁니다. 준우량 구간과, 승인 규칙이 비워 두는 한 가지 경우(점수는 우량인데 소득이 하한에 못 미치는 신청)를 같이 잡습니다. 조건은 AND 그룹 두 개를 OR로 묶은 모양입니다.
{
"type": "GROUP",
"operator": "OR",
"children": [
{
"type": "GROUP",
"operator": "AND",
"children": [
{
"type": "SINGLE",
"field": "credit_score",
"operator": "GREATER_THAN_OR_EQUAL",
"value": 580,
"valueType": "NUMBER"
},
{
"type": "SINGLE",
"field": "credit_score",
"operator": "LESS_THAN",
"value": 720,
"valueType": "NUMBER"
}
]
},
{
"type": "GROUP",
"operator": "AND",
"children": [
{
"type": "SINGLE",
"field": "credit_score",
"operator": "GREATER_THAN_OR_EQUAL",
"value": 720,
"valueType": "NUMBER"
},
{
"type": "SINGLE",
"field": "annual_income_usd",
"operator": "LESS_THAN",
"value": 40000,
"valueType": "NUMBER"
}
]
}
]
}
이 네 규칙이면 팩트가 갖춰진 신청자는 누구든 규칙 하나 이상에 걸립니다. 상한을 넘는 부채 비율은 거절에 걸리고, 그 아래에서는 하한 미만 점수가 점수 거절에, 준우량 구간과 소득이 하한에 못 미치는 우량 신청이 조건부에, 소득이 충분한 우량 점수가 승인에 걸립니다. "신청 한 건에 결정 하나"라는 제약은 이제 if 블록 네 개가 우연히 놓인 순서가 아니라 mutexMode라는 필드에 적혀 있습니다.
이제 기준값은 데이터입니다. 소득 하한을 바꾸는 일은 초안 버전에서 값 하나를 고치는 일이고, "5월 14일에 우량 점수 기준이 얼마였는가"는 git blame이 아니라 버전 이력이 답합니다.
변경 영향 시뮬레이션 전략
리스크가 부채 비율 상한을 0.50에서 0.45로 내린다고 합시다. 이 값이 실제 신청에 닿기 전에, 변경이 미칠 파장을 미리 잴 수 있습니다. 결정이 바뀌는 신청이 얼마나 되고, 각 신청이 어느 쪽으로 바뀌는지입니다. 운영 중인 버전을 복제해 기준값 하나만 고치면, 아직 트래픽을 받지 않는 대상 버전이 됩니다.
이건 금액이 아니라 건수를 묻는 질문이라, 분석 대상 팩트는 필요 없습니다. 그 항목은 비워 둬도 됩니다. includeRuleStats만 켜면 충분합니다. 규칙마다 매칭률이 나오는데, 대상 버전 매칭률에서 비교 기준 버전 매칭률을 뺀 차이가 곧 결정 구성이 옮겨 간 양입니다. 상한을 더 조인 거절이 신청을 얼마나 더 거부하는지, 그 신청들이 어느 규칙에서 빠져나왔는지를 보여 줍니다.
lexq analytics simulation start --json '{
"policyVersionId": "<candidate-version-id>",
"dataset": {
"type": "HISTORICAL",
"source": "EXECUTION_LOGS",
"from": "2026-05-01",
"to": "2026-05-31"
},
"options": {
"baselinePolicyVersionId": "<baseline-version-id>",
"includeRuleStats": true,
"maxRecords": 50000
}
}'
배포할지 말지는 두 가지로 판단합니다. 첫째, 거절 규칙의 매칭률 변화(대상 버전에서 비교 기준 버전을 뺀 값)가 리스크가 감당하기로 한 선 안에 들어와야 합니다. 그 숫자가 늘어나는 거부 건수이자, 거기서 나가는 거절 통지의 양입니다. 둘째, 변경이 건드리지 않은 규칙은 매칭률이 그대로여야 합니다. 이번 수정은 기준값 하나만 옮겼다고 했고, 규칙별 통계가 그 말이 사실인지 확인해 줍니다. 시뮬레이션은 외부 호출을 모킹으로 대체합니다. 과거 데이터를 읽기만 할 뿐 아무것도 쓰지 않습니다.
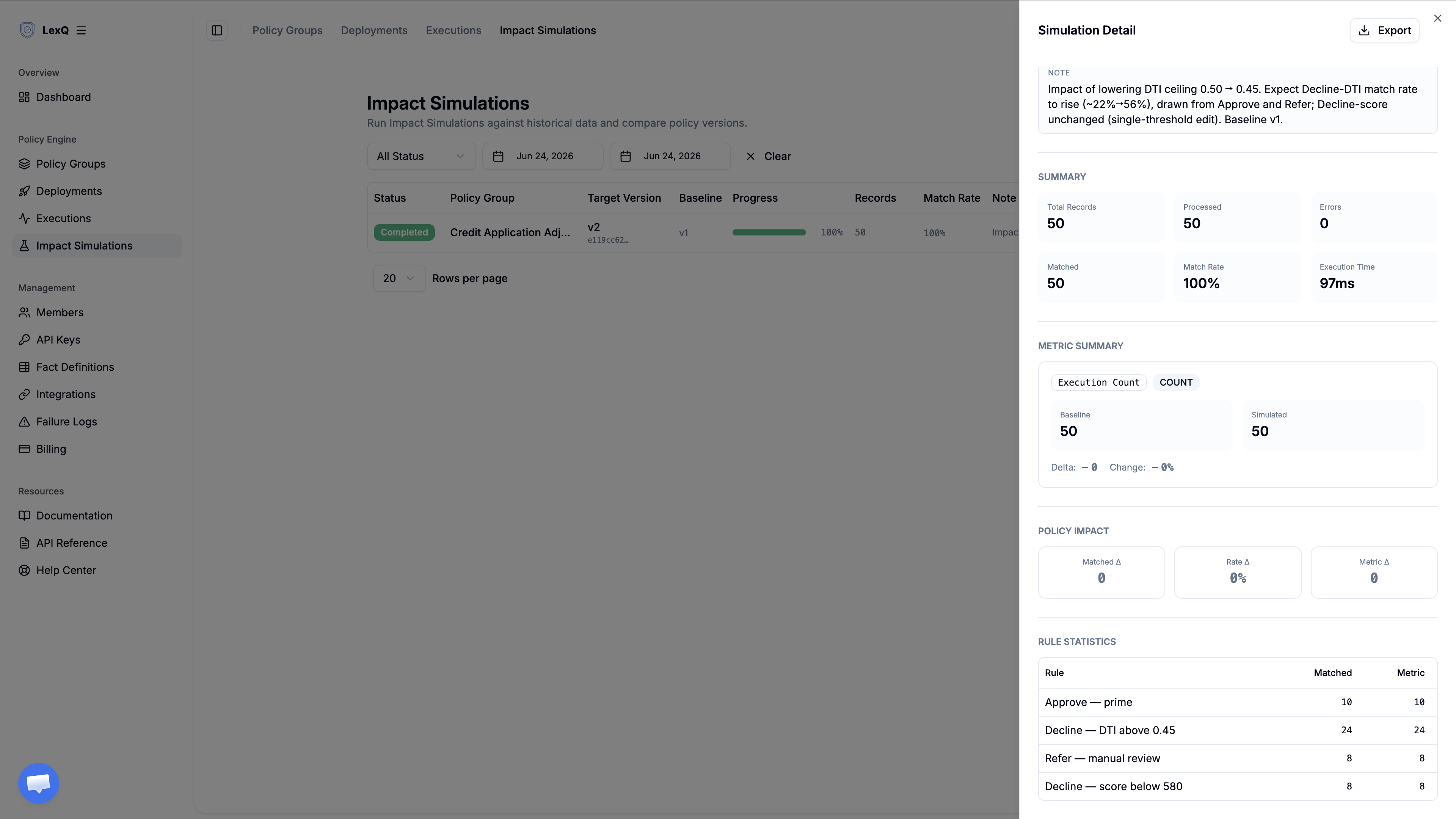
아직 운영 트래픽이 없다면, 대표 데이터셋을 올려 같은 비교를 돌리면 됩니다. 모든 구간이 들어가고 점수와 비율이 각 기준값 언저리에 몰린 신청으로 구성하면, 결정이 바뀌는 경우가 빠짐없이 들어갑니다.
의사결정 트레이스 출력
신호가 부딪치는 경우를 드라이런으로 돌려 봅니다. 점수 760, 소득 120,000, 부채 비율 0.55입니다.
{
"result": "SUCCESS",
"data": {
"traceId": "a7f3c0e1-...",
"inputFacts": {
"credit_score": 760,
"annual_income_usd": 120000,
"dti_ratio": 0.55
},
"mutatedFacts": {},
"generatedVariables": {
"credit_decision": "DECLINED",
"decision_reason": "Debt-to-income ratio above 0.50"
},
"executionTraces": [ ... ],
"decisionTraces": [
{
"ruleName": "Decline — DTI above 0.50",
"status": "SELECTED",
"reasonCode": "FINAL_WINNER",
"reasonDetail": null
},
{
"ruleName": "Decline — score below 580",
"status": "NO_MATCH",
"reasonCode": "CONDITION_MISMATCH",
"reasonDetail": null
},
{
"ruleName": "Approve — prime",
"status": "BLOCKED",
"reasonCode": "MUTEX_PRIORITY_LOST",
"reasonDetail": "Winner=[Decline — DTI above 0.50], Strategy=HIGHEST_PRIORITY"
},
{
"ruleName": "Refer — manual review",
"status": "NO_MATCH",
"reasonCode": "CONDITION_MISMATCH",
"reasonDetail": null
}
]
}
}
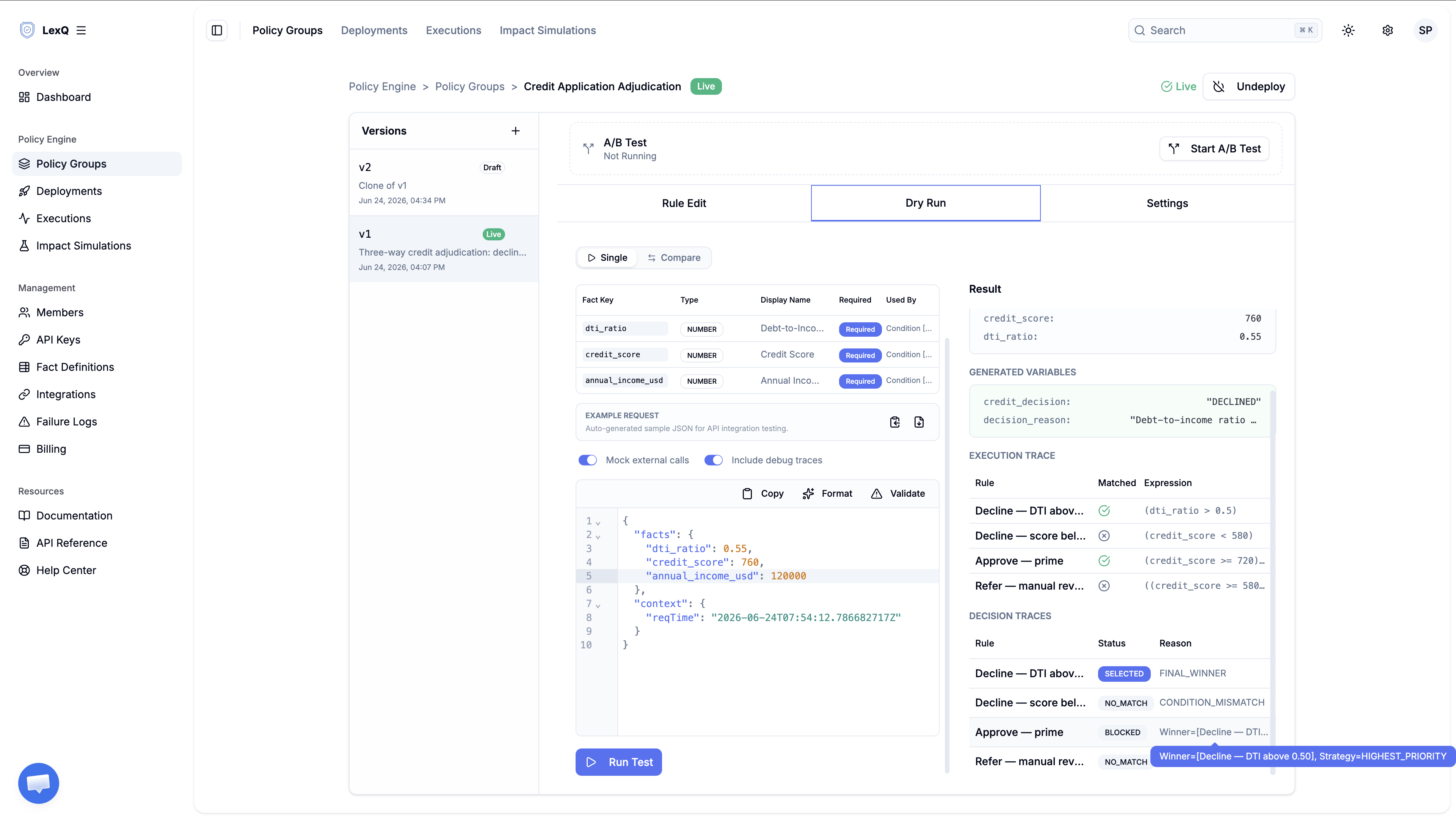
신청이 읽는 결정은 generatedVariables에 담깁니다. credit_decision이 DECLINED이고, decision_reason에는 규칙이 적은 문자열이 들어 있습니다. mutatedFacts는 비어 있습니다. 이 맵에는 입력으로 들어온 팩트 중 값이 바뀐 것만 담기는데, SET_FACT는 기존 팩트를 바꾸는 게 아니라 새 팩트를 만드는 액션이라 결정이 generatedVariables 쪽으로 갑니다. KYC 차단의 is_blocked가 담기던 곳과 같고, 이유도 같습니다. __delta도 없습니다. 그 키는 규칙이 값을 바꾼 숫자 팩트에만 붙는데, 범주형 결정은 숫자를 건드리지 않으니까요.
결정이 설명되는 자리는 트레이스입니다. 승인 규칙은 분명히 걸렸습니다. 점수 760과 소득 120,000이 조건을 채웁니다. 다만 우선순위가 더 높은 거절에 상호 배타 경쟁에서 밀렸고, 이 사실이 BLOCKED / MUTEX_PRIORITY_LOST로 남으며 어느 규칙이 선택됐는지가 reasonDetail에 적힙니다. 그렇게 남은 탈락이 곧 거절 사유입니다. "점수를 무시했다"가 아니라 "점수는 자격을 채웠지만, 상한을 넘는 부채 비율이 그보다 앞섰다"입니다. SELECTED 규칙의 이름은 대출 기관이 신청자에게 건네는 사유이고, 무엇이 선택됐고 무엇이 어떤 이유로 탈락했는지 그 전체 그림은 기관이 감사용으로 보관하는 답입니다. 각 규칙이 어떤 조건으로 평가됐는지는 위 드라이런 화면의 실행 트레이스 표에서 볼 수 있습니다.
같은 신청자를 부채 비율 0.30으로 다시 돌리면 충돌이 사라집니다.
{
"result": "SUCCESS",
"data": {
"traceId": "b2e9d4a0-...",
"inputFacts": {
"credit_score": 760,
"annual_income_usd": 120000,
"dti_ratio": 0.30
},
"mutatedFacts": {},
"generatedVariables": {
"credit_decision": "APPROVED",
"decision_reason": "Score 720+ with income 40000+"
},
"executionTraces": [ ... ],
"decisionTraces": [
{
"ruleName": "Decline — DTI above 0.50",
"status": "NO_MATCH",
"reasonCode": "CONDITION_MISMATCH",
"reasonDetail": null
},
{
"ruleName": "Decline — score below 580",
"status": "NO_MATCH",
"reasonCode": "CONDITION_MISMATCH",
"reasonDetail": null
},
{
"ruleName": "Approve — prime",
"status": "SELECTED",
"reasonCode": "FINAL_WINNER",
"reasonDetail": null
},
{
"ruleName": "Refer — manual review",
"status": "NO_MATCH",
"reasonCode": "CONDITION_MISMATCH",
"reasonDetail": null
}
]
}
}
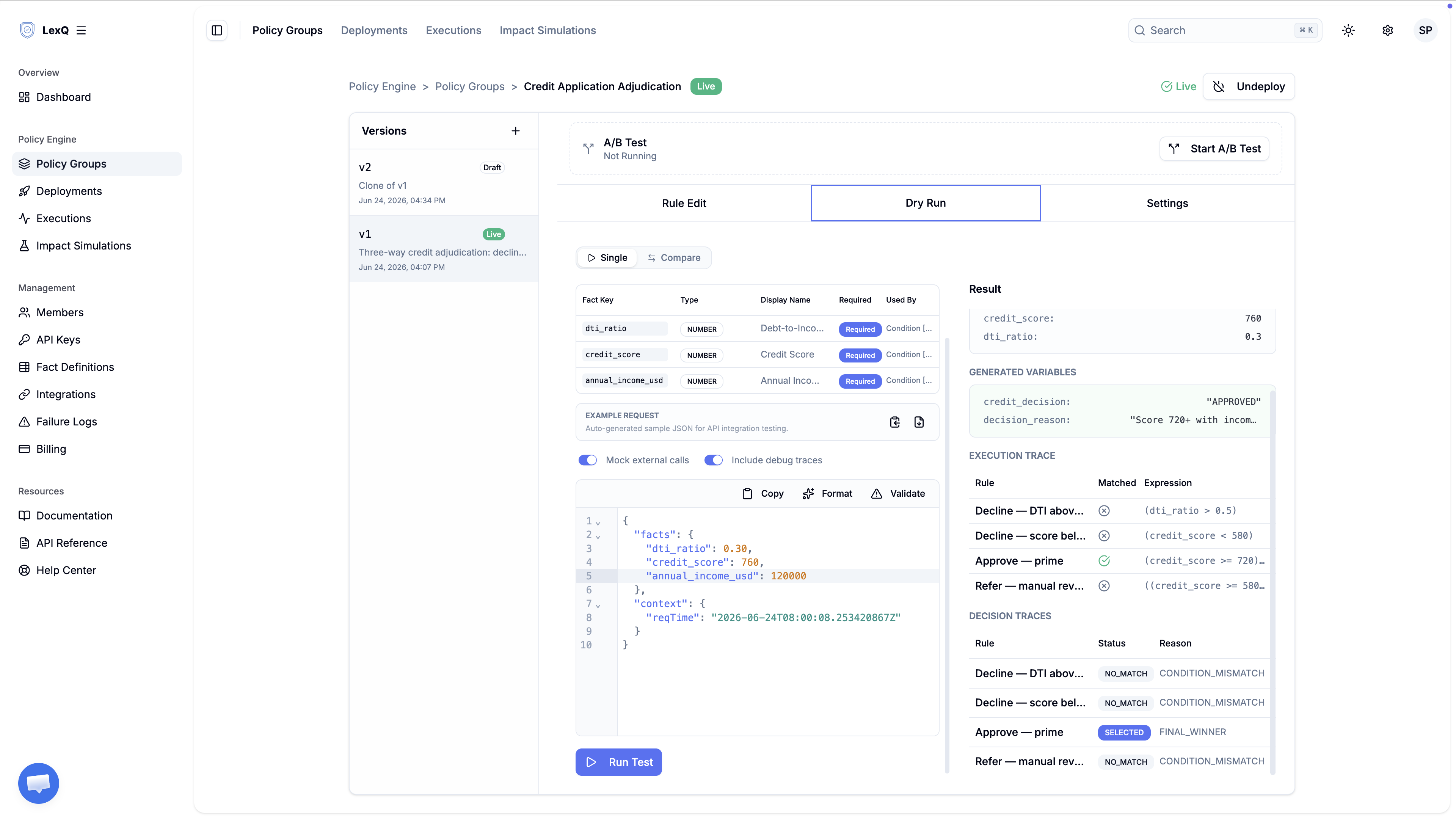
거절이 더는 걸리지 않으니 승인 규칙만 실행됩니다. SELECTED 하나에 NO_MATCH 셋, credit_decision은 APPROVED가 됩니다. 깔끔한 승인이든 다툼이 있는 거절이든 트레이스 구조는 똑같고, 달라지는 건 어느 규칙이 SELECTED를 차지하느냐뿐입니다.
엣지 케이스
이 패턴의 핵심은 특정 기준값이 아니라 단일 결정 지점입니다. 그 언저리의 몇 경우는 의식적인 선택을 요구합니다.
- 기준값과 딱 걸치는 신청자.
GREATER_THAN은 부채 비율이 정확히 0.50인 신청을 거절에서 통과시킵니다. "상한"을 허용되는 최대 비율로 본 것입니다. 정책이 "그 값부터 거절"이라면 연산자는GREATER_THAN_OR_EQUAL입니다. 같은 선택이 720 점수 경계에도 똑같이 걸립니다. 한 번 정해 연산자에 적어 두면, 기록된 조건식이 지금 어느 해석으로 도는지 보여 줍니다. - 빠진 팩트.
dti_ratio가 없는 페이로드는 조용히 지나가지 않습니다. 엔진은 임의의 기본값으로 메우는 대신 빠진 팩트 이름을 담아 에러를 던집니다. 호출하는 쪽은 에러로 끝난 실행을 미심사로 처리해야 하고, 조용한 거절이나 조용한 승인으로 넘겨선 안 됩니다. 엔진이 추측을 거부했으니, 애플리케이션이 대신 추측해서도 안 됩니다. - 신청자에게 줘야 할 사유. 결정이 내려질 때마다
decision_reason이 남고,SELECTED규칙 이름은 어느 규칙이 그 결과를 냈는지 가리킵니다. 둘은 일부러 갈라 둡니다. 규칙 이름은 내부용 기록이고,decision_reason은 신청자에게 보일 수 있게 다듬은 문장입니다. 둘 다 결정마다 남으니, 거절 통지는 짜 맞추는 일이 아니라 필드 하나 읽는 일입니다. - 과거 이력에 기대는 결정. 이 패턴은 한 시점의 팩트만 보고 신청 한 건을 결정합니다. 지난 행동에 기대는 규칙(조회를 거듭하며 떨어지는 점수, 이번 달 세 번째 신청)이라면 누적 팩트(
INCREMENT_FACT)와 시간 창이 필요하고, 이건 실패하는 방식이 다른 별도 패턴이라 여기서는 다루지 않습니다. - 어느 규칙에도 걸리지 않는 신청. 조건부는 준우량 구간과, 소득이 하한에 못 미치는 우량 신청을 사람에게 넘기는 분명한 결정입니다. 빠뜨린 경우가 아니라 어엿한 결정입니다. 누가 구간을 잘못 손봐 빈틈이 생기면, 그 틈에 떨어진 신청은 어디에도 걸리지 않습니다. 그래도 엔진은 아무도 고르지 않은 쪽으로 대충 넘기지 않고 에러로 멈춥니다. 빈틈에 빠진 신청은 조용히 승인되거나 거부되지 않고, 곧바로 사람 손으로 넘어갑니다.
운영 배포
두 조건을 통과한 대상 버전은 배포해서 운영에 올립니다. 배포 순간의 규칙 스냅샷은 해시로 봉인되어 무결성이 검증되고, 누가 언제 어떤 버전을 올렸는지가 기록으로 남습니다.
기준값 변경은 트래픽을 쪼개 조금씩 적용하지 않고, 모든 신청에 한 번에 적용합니다. A/B 테스트로 트래픽을 나누면 일부 신청은 새 기준값으로, 나머지는 이전 기준값으로 판정됩니다. 점수와 소득과 부채 비율이 같은 두 신청자가 어느 쪽에 떨어졌는지만으로 다른 결정을 받는다는 뜻입니다. 부분 적용을 견디는 할인이라면 그 정도는 괜찮지만, 여신 결정에서는 같은 사실에 들쭉날쭉한 판정 자체가 결함이지 안전장치가 아닙니다. 배포해도 된다는 확신은 카나리가 아니라 변경 영향 시뮬레이션에서 옵니다. 배포가 더해 주는 건 운영 데이터로 하는 확인뿐입니다. 규칙별 운영 매칭률을 시뮬레이션 매칭률과 맞대어 봅니다.
다음 두 신호 중 하나라도 보이면 곧바로 롤백합니다.
- 바꾼 규칙의 운영 매칭률이 시뮬레이션 매칭률에서 벗어날 때. 운영 신청자 분포가 시뮬레이션에 쓴 과거 구간과 다르다는 뜻이고, 승인했던 파장 범위는 더는 유효하지 않습니다.
- 시뮬레이션이 변동 없다고 본 구간에서 결정이 나타날 때. 운영에 들어오는 팩트가 대상 버전을 잴 때 쓴 데이터셋과 다르다는 뜻입니다.
두 버전이 같은 신청을 어떻게 다르게 판정하는지 봐야 한다면, A/B 테스트를 섀도 모드로 돌립니다. 모든 신청을 두 버전에 똑같이 흘려보내되 실제 결정은 한 버전으로만 내리고, 운영 결정은 그대로 둔 채 두 결과의 차이만 확인합니다. 그러면 비교는 비교대로 하면서, 신청자는 모두 한 버전의 결정을 받습니다. 롤백하면 정책 그룹이 이전 버전으로 돌아가고, 롤백했다는 사실까지 배포 이력에 남습니다. 버전이 운영에 올라가면, "5월에 부채 비율로 거부된 신청이 몇 건인가"에는 규칙별 통계가 상시 답이 됩니다. 규칙과 버전으로 범위를 좁힌 실행 이력 조회면 되지, 로그를 파헤칠 일이 아닙니다. 그리고 "5월 14일에 운영 중이던 우량 점수 기준"은 버전 이력과 배포 기록에 그대로 있습니다.
LexQ가 어떻게 동작하는지 playground에서 직접 확인해보세요.